Sparse Coding
Sparse coding is a class of unsupervised methods for learning sets of over-complete bases to represent data efficiently. —— 过完备的基,无监督 The aim of sparse coding is to find a set of basis vectors
such that we can represent an input vector
as a linear combination of these basis vectors:
over-complete
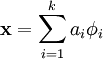
k n The advantage of having an over-complete basis is that our basis vectors are better able to capture structures and patterns inherent in the input data. the coefficients ai are no longer uniquely determined
过完备的基能发掘出数据的内在结构和模型,但是其系数表示将不唯一
Here, we define sparsity as having few non-zero components or having few components not close to zero. The requirement that our coefficients ai be sparse means that given a input vector, we would like as few of our coefficients to be far from zero as possible. The choice of sparsity as a desired characteristic of our representation of the input data can be motivated by the observation that most sensory data such as natural images may be described as the superposition of a small number of atomic elements such as surfaces or edges. 原子图像的叠加 Other justifications such as comparisons to the properties of the primary visual cortex have also been advanced.
We define the sparse coding cost function on a set of m input vectors as
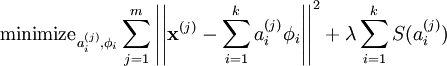
where S(.) is a sparsity cost function which penalizes ai for being far from zero.
稀疏惩罚项
We can interpret the first term of the sparse coding objective as a reconstruction term which tries to force the algorithm to provide a good representation of
Although the most direct measure of sparsity is the "L0" norm (
), it is non-differentiable (不可微) and difficult to optimize in general. In practice, common choices for the sparsity cost S(.) are the L1 penalty
and the log penalty
.
In addition, it is also possible to make the sparsity penalty arbitrarily small by scaling down ai and scaling
to be less than some constant C. The full sparse coding cost function including our constraint on
is
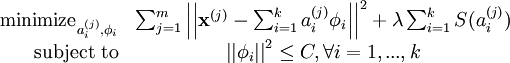
Probabilistic Interpretation
到目前为止,我们所考虑的稀疏编码,是为了寻找到一个稀疏的、超完备基向量集,来覆盖我们的输入数据空间。现在换一种方式,我们可以从概率的角度出发,将稀疏编码算法当作一种“生成模型”。
我们将自然图像建模问题看成是一种线性叠加,叠加元素包括 k 个独立的源特征
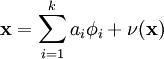
我们的目标是找到一组特征基向量
尽可能地近似于输入数据的经验分布函数
。一种实现方式是,最小化
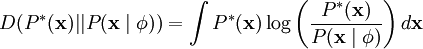
因为无论我们如何选择
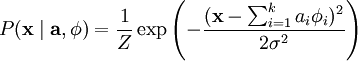
为了确定分布
。假定我们的特征变量是独立的,我们就可以将先验概率分解为:
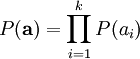
此时,我们将“稀疏”假设加入进来——假设任何一幅图像都是由相对较少的一些源特征组合起来的。因此,我们希望 ai 的概率分布在零值附近是凸起的,而且峰值很高。一个方便的参数化先验分布就是:
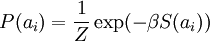
这里 S(ai) 是决定先验分布的形状的函数。
当定义了
和
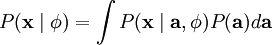
那么,我们的问题就简化为寻找:
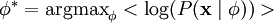
这里 < . > 表示的是输入数据的期望值。
不幸的是,通过对
的积分计算
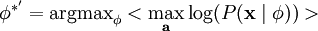
跟之前一样,我们可以通过减小 ai 或增大
最后,我们可以定义一种线性生成模型的能量函数,从而将原先的代价函数重新表述为:
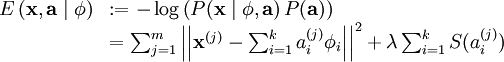
其中 λ = 2σ2β ,并且关系不大的常量已被隐藏起来。因为最大化对数似然函数等同于最小化能量函数,我们就可以将原先的优化问题重新表述为:
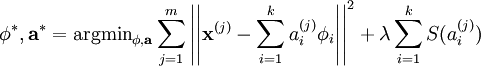
使用概率理论来分析,我们可以发现,选择 L1 惩罚和
惩罚作为函数 S(.) ,分别对应于使用了拉普拉斯概率
和柯西先验概率
。
Learning
使用稀疏编码算法学习基向量集的方法,是由两个独立的优化过程组合起来的。第一个是逐个使用训练样本
如果使用 L1 范式作为稀疏惩罚函数,对
的学习过程就简化为求解 由 L1 范式正则化的最小二乘法问题,这个问题函数在域
用 L2 范式约束来学习基向量,同样可以简化为一个带有二次约束的最小二乘问题,其问题函数在域
根据前面的的描述,稀疏编码是有一个明显的局限性的,这就是即使已经学习得到一组基向量,如果为了对新的数据样本进行“编码”,我们必须再次执行优化过程来得到所需的系数。这个显著的“实时”消耗意味着,即使是在测试中,实现稀疏编码也需要高昂的计算成本,尤其是与典型的前馈结构算法相比。